

Building Modern Serverless API's with AWS: DynamoDB, Lambda, and API Gateway(Part 2)
Design the primary key for the DynamoDB table and enable the core access patterns


Part 1(phatrabbitapps.com/building-modern-serverle..)
Introduction
Welcome to part 2 of Building Modern Serverless API's with AWS. In part 1, we looked at the entities(User, Product, Comment) our application needed and broke down the various access patterns for each of those entities.In this post, we would design the primary key for our DynamoDB table and also enable the core access patterns described in Part 1.
Primary Key Design
We are going to be storing all our entities in a single table, instead of 3 separate tables. In such a scenario, we have to make sure the primary key has a way to distinctly identify each entity and enable core actions on individual items.We have to use prefixes to distinguish between entity types. Using prefixes to distinguish between entity types can prevent collisions and assist in querying. For Example, for the User Entity, we will use USER# prefix, for Post entity, we would use POST# and COMMENT# for the Comment entity.
The above entities show three different kinds of data relationships. First, each user on your application will have a single user profile represented by a User entity in your table. Next, a user will have multiple posts represented in your application, and a post will have multiple comments. These are both one-to-many relationships.
We have to get a single user, as well as get all posts for a particular user sorted with a timestamp. Same thing with Post and Comments. We would query all comments for a particular post in a sorted manner too.
Therefore, our primary key would be a composite primary key. That is, it'll be made up of a Partition key(PK) and a Sort key(SK). In other words, a HASH and RANGE value.
With this in mind, let’s use the following pattern for HASH and RANGE values for each entity type:
| Entity | Hash | Range |
|---|---|---|
| User | "USER#UserId | #METADATA#UserId |
| Post | USER#UserId | POST#PostId#Timestamp |
| Comment | POST#PostId#Timestamp | COMMENT#CommentsId#Timestamp |
Adding UserId to the Range value makes the Range value unique across different User entities and enables even partitioning if you use this column as a HASH key for an index. You can read about even partitions and data distributions here Second, the Post entity is a child entity of a particular User entity. The main access pattern for posts is to retrieve posts for a user ordered by date. Whenever you need something ordered by a particular property, you will need to include that property in your RANGE key to allow for sorting.
For the Post entity, use the same HASH key as the User entity, which will allow you to retrieve both a user profile and the user’s posts in a single request. For the RANGE key, use POST#PostId#TIMESTAMP to uniquely identify a post in your table.
Third, the Comment entity is a child entity of a particular Post entity. There is a one-to-many relationship to the Post entity. The partition key is POST#PostId#Timestamp# and the Sort Key is COMMENT#CommentsId#Timestamp which would enable us grab all comments for a given post ordered by date.
We could as well given the Comment entity Partition Key (USER#UserId) and Sort Key COMMENT## with PostId as one of its attributes. Then use a secondary key to query all comments ordered by date for a given post. We'll go with the first choice.
I took the liberty of modeling the table using the amazing NoSQL Workbench. Here are visual representations of all 3 entities.
User Entity
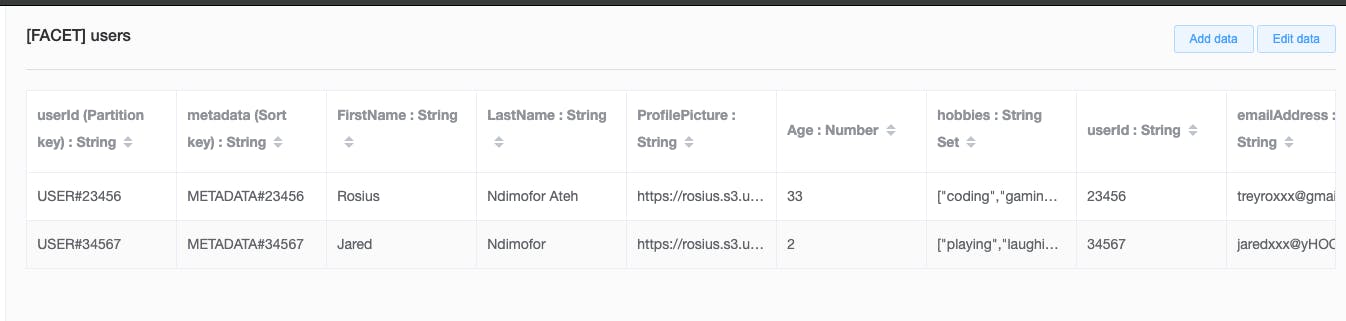 Take note of the Partition and Sort Key
Take note of the Partition and Sort Key
Post Entity
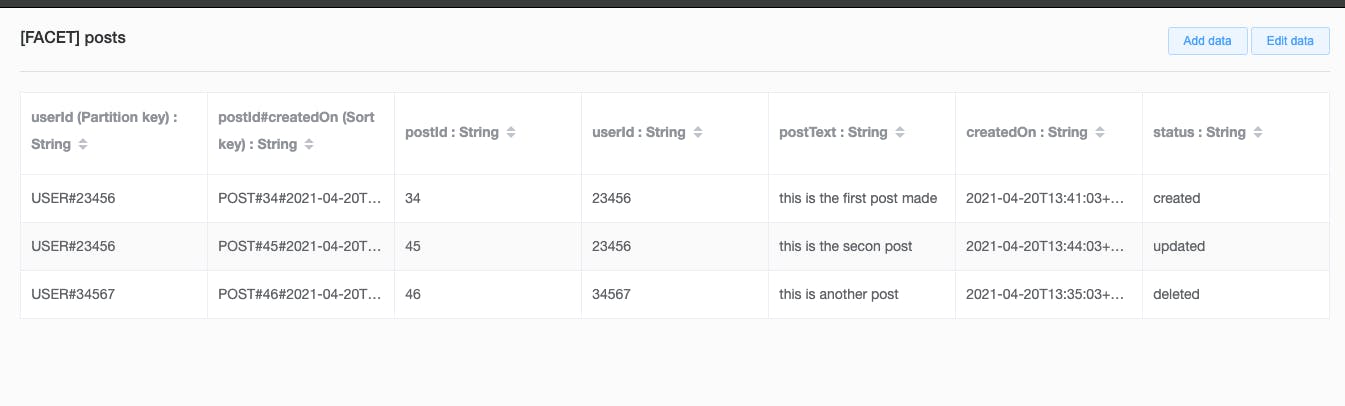 The Partition Key is User#UserId and the Sort key is POST#PostId#Timestamp.
The Partition Key is User#UserId and the Sort key is POST#PostId#Timestamp.
Comment Entity
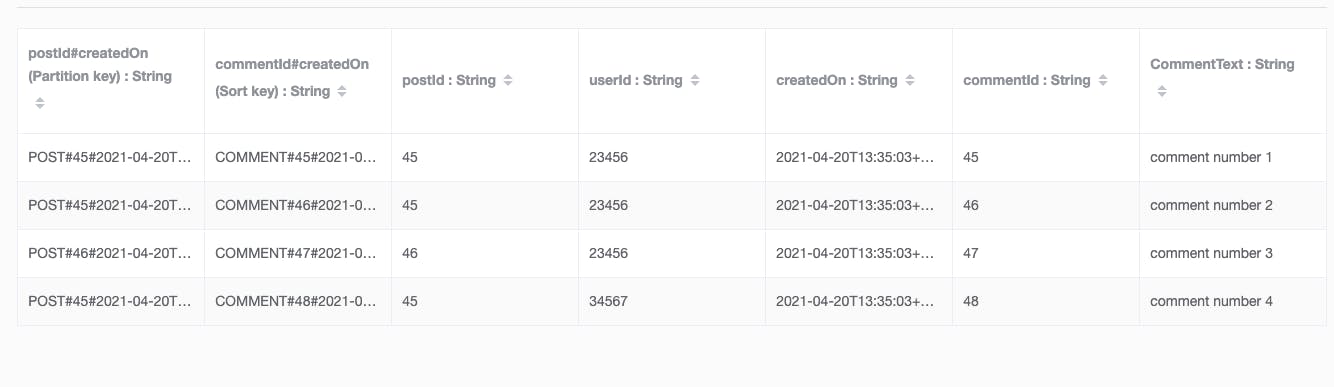
Now, here's an aggregate view of the complete table which I call "data". It contains all 3 entities.
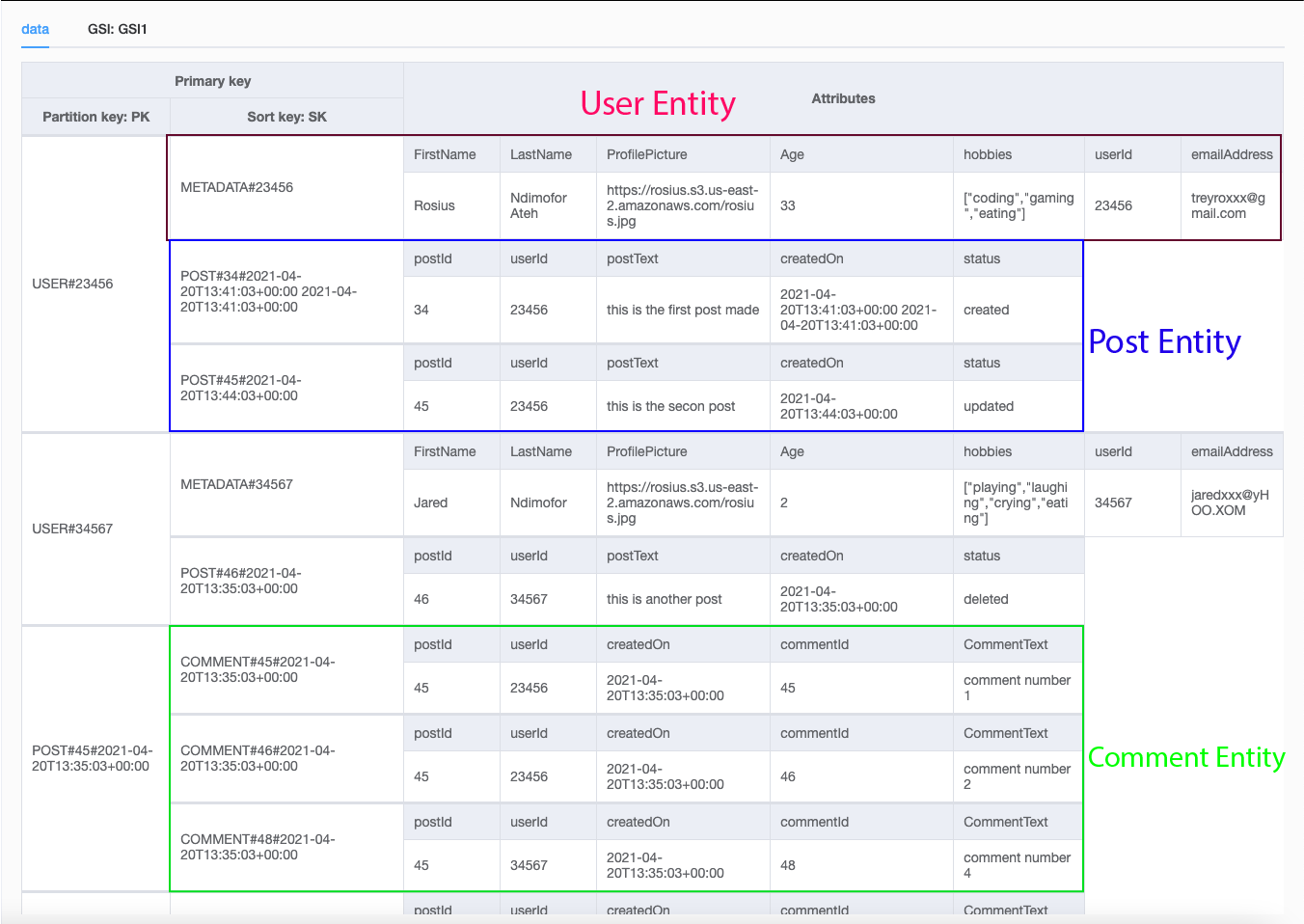
Looking at the table, here are the queries we can make
- Get a single user
- Get all posts for a given User ordered by date
- Get all comments for a given Post ordered by date
It'll also be good to get all posts, for a specific status. Our Post entity would support 3 status types.
- create
- updated
- deleted
I'll like to display a list of posts with status created or updated on my home tab.
Presently, the status field isn't a Partition Key. So we can't use it to query any data unless we create a Global Secondary Index (GS1) with it as a Partition Key.
With all that in mind, let's adjust the table to support GSI for status.
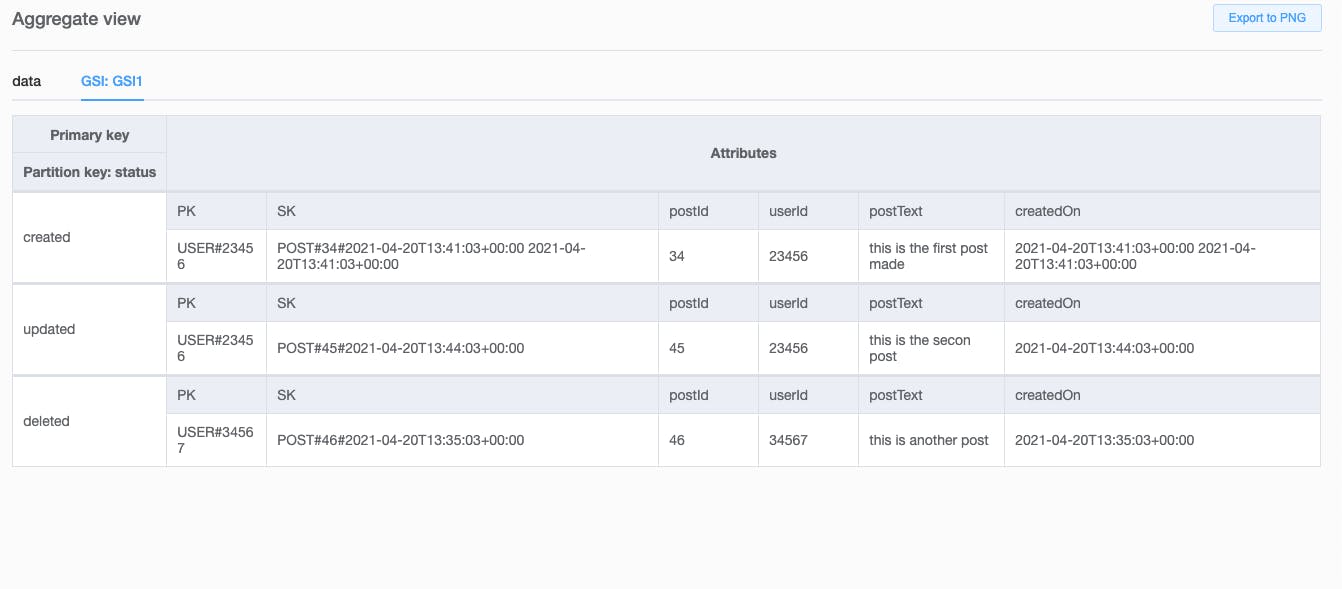
Now, we can query all posts for a given status.
Conclusion
In this post, we designed a primary key for our table and went through a couple of visual snippets of how our table would eventually look like when data is added to it. We also added a Global secondary Index in other to query a set of posts for a given status.With our current primary key design, we are able to satisfy the following access patterns:
- Create user profile (Write)
- Update user profile (Write)
- Get user profile (Read)
- Create Post (Write)
- Update a Post (Write)
- View posts for User (Read)
- View comments for posts (Read)
- View posts per status (Read)
Thanks for reading. Please leave feedback on what you think or if you loved it. Also, show a brother some love by leaving a like.
To be completely transparent with you, I ain't a master in this. So if you see any mistakes in the article, or if you have any suggestions for improvements, I'm more than willing to learn and adjust.
In the third post, we will start coding. I highly recommend you install AWS CLI, SAM CLI(including Docker).
Till next time my brothers and sisters.✌🏿