

Building Modern Serverless API's with AWS: DynamoDB, Lambda, and API Gateway(Part 1)
Data Modeling and Access Patterns in DynamoDB


Introduction
For the past 4 weeks, I've written a series called DynamoDB, Demystified. I coveredModeling.
- The Birth of NoSQL databases.
- What Amazon DynamoDB is, along with basic concepts such as Table, Item, Attributes, Global and local secondary indexes.
- Built applications to perform CRUD operations on a DynamoDB table.
- And also how to create and Query Global Secondary Indexes on a DynamoDB table.
Here's the article series. I recommended you go through it, because, this post assumes you are familiar with the basics discussed in that article series
Demystifying DynamoDb For Beginners
In this post, we will be looking at building an API for a social media application, backed by DynamoDB. When using DynamoDB, it is important to consider how you will access your data (your access patterns) before you model your data. Before we proceed, please make sure you have all these installed and configured on your computer
- AWS Cli
- AWS SAM CLI and Docker(Please install Docker)
AWS SAM is a command-line tool that makes it easy to create and configure serverless applications. In previous articles(How to build serverless Jamstack applications, we used the serverless framework which does the same thing as SAM, but it's offered by a third-party company. SAM is offered by Amazon.
Background
Let's assume we want to build a social media application where people can create user accounts, create public posts and make comments under posts. A user should be able to update their profile information and also update their post. Let's keep it streamlined that way.So here are the entities involved
- Users
- Posts
- Comments
Relationship Model
When modeling the entities of your application, the first step is to build a diagram that shows the relationship between each entity. That is, how entities relate with each other. In our app, we have 3 entities(Users, Posts and Comments).A user can have many posts and a post can have many comments. One post cannot belong to many users, neither can one comment belong to many posts. So there's a one to many relationship between the user and post and a one to many relationships between posts and comments.
The diagram below best illustrates the relationship.
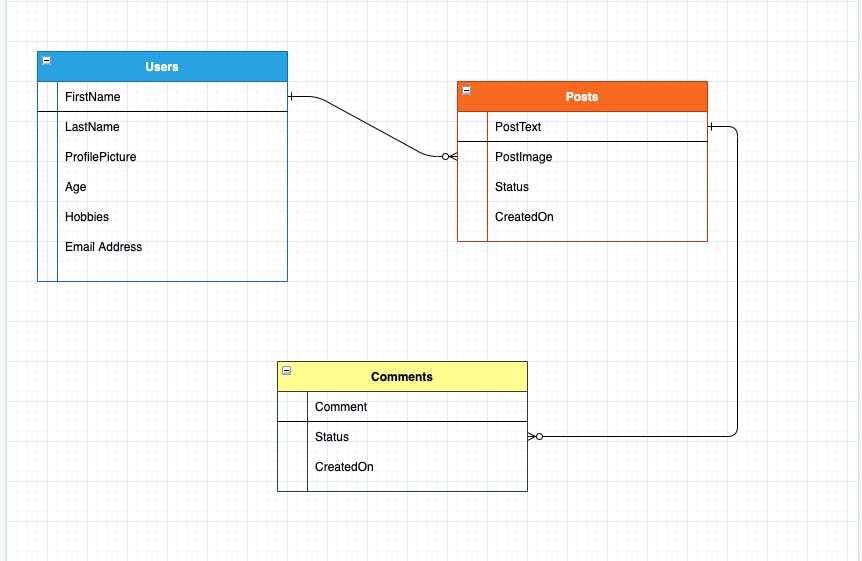
In a relational database system, you'll immediately know that you need a table for each entity. So that's 3 tables. And data would definitely be saved like so
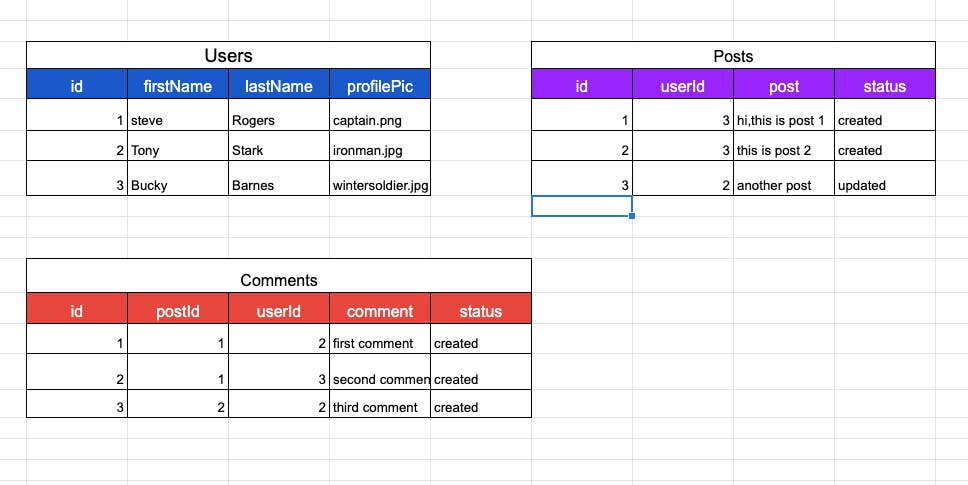 You see that in the post table, userId is a foreign key.It represents the user who made the post. Same thing with the comments table, where postId and userId are foreign keys representing the user who made the comment and the post where the comment was made.
A relational database is built for flexibility and can be a great fit for analytical applications. In relational data modeling, you start with your entities first.
You see that in the post table, userId is a foreign key.It represents the user who made the post. Same thing with the comments table, where postId and userId are foreign keys representing the user who made the comment and the post where the comment was made.
A relational database is built for flexibility and can be a great fit for analytical applications. In relational data modeling, you start with your entities first.
When you have a normalized relational model, you can satisfy any query pattern you need in your application.
With the above illustration, we can use joins to grab say, all comments for a single post.Or All posts for a particular user and a lot more. But as our application gets bigger, so do our joins get more complex and expensive to run.
Data retrieval becomes slower too.
NoSQL (nonrelational) databases are designed for speed and scale—not flexibility. Though the performance of your relational database may degrade as you scale up, horizontally scaling databases such as DynamoDB provides consistent performance at any scale. Some DynamoDB users have tables that are larger than 100 TB, and the read and write performance of their tables is the same as when the tables were smaller than 1 GB in size.
Modeling entities in a NoSQL database such as DynamoDB requires a shift in thinking.
Don't try to Normalize your table. That's relational database modeling thinking, which is an anti-pattern if applied to NoSQL.Data duplication in NoSQL databases is very essential.
Your DynamoDB table will often include different types of data in a single table. In our case, we’ll have Users, Posts, and Comments entities in a single table. In a relational database, this would be modeled as three separate tables.
Let's look at the access patterns for each of our entities
Access Patterns
Users
Users of our app would need to create a profile and fill in information such as firstName, lastName, profilePicture, etc.Users should be able to see other users' profiles. They should also be able to update their profile information.
With all that in mind, we have 3 access patterns
- Create user profile (Write)
- Update user profile (Write)
- Get user profile (Read)
Posts
Our app would allow users to upload and share posts with their friends. Some kind of Facebook stuff. I'm coming for you Facebook, wait and see. Users should be able to update their posts. They should also view other users' posts on their timelines.With all that in mind, we have 3 access patterns
- Create Post(Write)
- Update Post(Write)
- View user Posts(Read)
Comments
Finally, for the comments access pattern, users can make comments under posts. Users can view all comments for a post.So we have
- Create Comments(Write)
- View Comments for each post(Read)
Conclusion
We have now mapped out all of our access patterns for our API. In the next post, We will map out the primary key, secondary indexes, and attributes in our table. Once we are confident the planning phase is complete, we'll then move forward with implementation. Thanks for taking out the time to check this out.
If you have any questions or comments, please leave them below and I'll get to it ASAP.
If you loved it, please leave a like 😉 Take care and see you in the next post.
Happy Coding ❤️