

Building Serverless Applications with Amplify,VueJs/NuxtJs, and GraphQL(Part 1)


It's without a doubt that AWS Amplify is becoming the favorite framework for building full-stack serverless mobile and web applications.
With Amplify, you can configure app backends and connect your app in minutes, deploy static web apps in a few clicks, and easily manage app content outside the AWS console. And they are in heavy support of graphQL as the main query language for your APIs.
In this post series, we'll be building a beautiful graphQL driven serverless web app using vue, AWS Amplify, and AWS Appsync.
Prerequisites
In order to complete this post series, you'll need basic knowledge of GraphQL and VueJs. You'll also need to know a little bit about AWS APPSYNC.With that said, let's gets started.
Use Case and Access Patterns
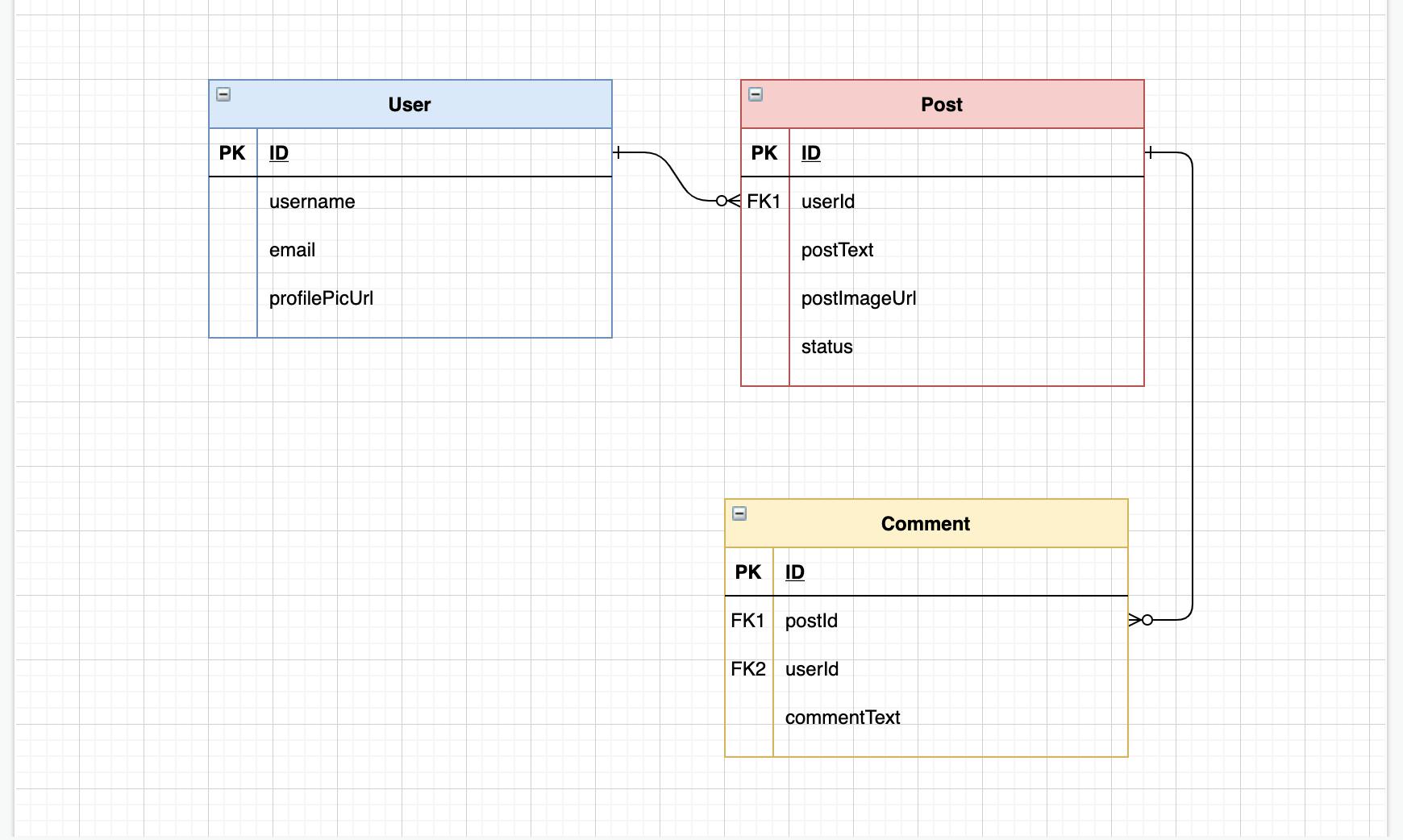
We want to build a simple social media application where users can create a user account, create posts and make comments under each post. So here are our entities and data access patterns.Entities
- User
- Post
- Comment
Relationship between models
One user can create multiple posts. But one post can only belong to a single user. So that's a one-to-many relationship. Same thing for comments. One post can have multiple comments, and one comment can only belong to one post.So we have 2 one-to-many relationships. Here's a visual representation of the relationships between the models.
Access Patterns
- Create, Read, Update, Delete user account.
- Create, Read, Update, Delete post.
- Create, Read, Update, Delete Comments.
- Search User account by email.
- Fetch All comments by postId
- Fetch all posts by status
The GraphQL Transform provides a simple to use abstraction that helps you quickly create backends for your web and mobile applications on AWS. With the GraphQL Transform, you define your application’s data model using the GraphQL Schema Definition Language (SDL) and the library handles converting your SDL definition into a set of fully descriptive AWS CloudFormation templates that implement your data model.
So based on the access patterns above, here's how the backend for your application would be.
type User @model
@key(name:"byEmail",fields:["email"],queryField:"getUserByEmail")
@auth(rules:[
{ allow: owner },
{ allow: private, operations: [read] }
]) {
id: ID!
username: String!
email:String!
profilePicUrl:String!
posts: [Post] @connection
}
type Post @model
@auth(rules:[
{ allow: owner },
{ allow: private, operations: [read] }
])
{
id: ID!
userID:ID!
postText: String!
postImageUrl:String!
status:Status!
user: User @connection(fields:["userID"])
comments: [Comment] @connection
}
type Comment @model
@auth(rules:[
{ allow: owner },
{ allow: private, operations: [read] }
]) {
id: ID!
commentText: String!
postID:ID!
userID:ID!
post: Post @connection(fields:["postID"])
user:User @connection(fields:["userID"])
}
enum Status {
CREATED
UPDATED
DELETED
}
The GraphQL Transform simplifies the process of developing, deploying, and maintaining GraphQL APIs. With it, you define your API using the GraphQL Schema Definition Language (SDL) and can then use automation to transform it into a fully descriptive cloudformation template that implements the spec.
Let's move through the above schema line by line.
@model
type User @model
@model is a directive, which defines top level object types in your API that are backed by Amazon DynamoDB. So, every type annotated with @model is a DynamoDB table
Therefore, our application would have 3 tables.
- User
- Post
- Comment
@key
@key(name:"byEmail",fields:["email"],queryField:"getUserByEmail")
@key is a directive used for creating custom indexes in your application. It has 3 arguments.
name
When provided, specifies the name of the secondary index. When omitted, specifies that the @key is defining the primary index. You may have at most one primary key per table and therefore you may have at most one @key that does not specify a name per @model type.Our secondary index, in this case, is byEmail.
fields
A list of fields that should comprise the @key, used in conjunction with an @model type. The first field in the list will always be the HASH key. email is the hash key. If two fields are provided the second field will be the SORT key. If more than two fields are provided, a single composite SORT key will be created from a combination of fields[1...n]. All generated GraphQL queries & mutations will be updated to work with custom @key directives. Read my article DynamoDB,Demystified to learn more about Partition and Sort Keys, Secondary Index Keys in a problem solving mannner.queryField
When defining a secondary index (by specifying the name argument), this specifies that a new top-level query field that queries the secondary index should be generated with the given name.@auth
@auth(rules:[
{ allow: owner },
{ allow: private, operations: [read] }
])
@auth is a directive for providing authorization to your API. Authorization is required for applications to interact with your GraphQL API. Object types that are annotated with @auth are protected by a set of authorization rules giving you additional controls.
The above snippet gives Create, Read, Update and Delete access to the owner of the data and then gives only Read access to an authenticated user.
id: ID!
username: String!
email:String!
profilePicUrl:String!
The above code defines the attribute and their respective types for our application. Bear in mind that these attributes act as fields in the DynamoDB table.
The ! at the end of the attribute types marks it as non-nullable. So the field can't be omitted when a mutation occurs.
@connection
posts: [Post] @connection
The @connection directive enables you to specify relationships between @model types. Currently, this supports one-to-one, one-to-many, and many-to-one relationships. You may implement many-to-many relationships using two one-to-many connections and a joining @model.
The user and post entity share a one-to-many relationship. So we have to add a post attribute in the user entity which takes a list of posts [Post].
post:[Post]
These last 2 lines in the Post model creates the relationship between a user and post entity.
user: User @connection(fields:["userID"])
comments: [Comment] @connection
@connection(fields:["userID"]) indicates that, the userId field should be queried to get the User Object for that post. @connection on the comments field only creates the relationship between the comment and the post entity
The rest of the schema simply repeats what we've already looked at.
Conclusion
In this post, we looked at the- Application use case
- Data access patterns.
- GraphQL Schema
- Directives such as model,keys,auth and connections,
We'll start building the application in Part 2 Thanks a lot for checking this out, any feedback would be greatly appreciated. I do a lot of writing about serverless and DynamoDB. Building Modern Serverless API's with AWS: DynamoDB, Lambda, and API Gateway
Stay safe✌🏿