Refactoring to Serverless. Improving app performance with Express Step functions

I love creating and writing about the creation of software.
Introduction
Serverless computing is a cloud-based approach to application development that eliminates the need for provisioning and managing servers. Instead, developers focus on writing code that is triggered by events such as HTTP requests or database changes. The cloud provider then executes the code on demand and scales the underlying infrastructure up or down as needed. This frees developers from worrying about server provisioning, capacity planning, and maintenance, so they can focus on building great applications.
In order words, Serverless computing is like buying a game console instead of building your own gaming rig.
Serverless Cloud providers provide a suite of beautifully crafted services to help developers build and automate their applications.
In today’s fast-paced world, businesses need to find ways to improve the performance of their applications.
One way to do this is through code automation.
In Serverless Development, it’s recommended to refactor application code with direct service integration code or platform code for a couple of reasons such as.
- Increased performance, as automated code is more efficient than manually written code.
- Increased Productivity as you get to write and manage less code. Bear in mind, code is a liability.
- Reduced errors.
- Increased Scalability And a lot of others.
In his book REFACTORING, Martin Fowler describes refactoring as
A controlled technique for improving the design of an existing code base by altering its internal structure without changing its external behavior.
In this post, we’ll look at a real-life use case in which part of an application’s code will be replaced with platform code, thereby drastically improving the overall performance of the application as deduced through a load test.
The Problem
2 years ago, I created a proof of concept for a Nanny booking application. I wanted to learn Event Driven Architecture, and what better way to learn than building?
Commercial Break.
Educloud Academy is a cloud learning platform for students who wish to learn by building. It has a couple of workshops for level 200 and 300 students and 2 workshops are added monthly. If you are new to Serverless Development, start your journey here https://www.educloud.academy/
Fast forward to 2023(2 years later), I decided to review the code and make changes, based upon my improved understanding of Serverless and application development in general.
One endpoint stood out the most to me. It's called book a nanny endpoint.
Before talking specifically about this endpoint, here’s a recap of how the application works.
There are 2 types of users in the application
- Admin (Systems administrators)
- Parent
- Nanny
Each of these users is restricted to certain endpoints using Cognito groups
A Parent can post jobs, leave nanny reviews, etc.
Nanny’s can apply for those jobs.
A parent can then choose the nanny who’s job application makes the most sense to them. A process known as book a nanny
Once this is done, all the other job applications are discarded(status changed to DECLINED).
The book a nanny endpoint had a Lambda function as a GraphQL resolver and carried out the following actions in series.
- Getting all applications for the job in particular.
- Accepting one of the job applications(changing application status to
ACCEPTED), - Declining all other job applications(changing application status to `DECLINED),
- Closing the job, so that it won't be available anymore for applying to(changing job status to CLOSED).
Let’s look at the code breakdown of each of these steps, as written in the lambda function.
Getting all applications for the job in particular
response_items = table.query(
IndexName="jobApplications",
KeyConditionExpression=Key("GSI1PK").eq(f"JOB#{jobId}"),
ScanIndexForward=False,
)
Accepting one of the job applications(changing application status to ACCEPTED) and Closing the job, so that it won't be available anymore for applying to(changing job status to CLOSED.
response = client.transact_write_items(
TransactItems=[
{
"Update": {
"TableName": os.environ["TABLE_NAME"],
"Key": {
"PK": {"S": f"USER#{username}"},
"SK": {"S": f"JOB#{jobId}"},
},
"ConditionExpression": "username = :username",
"UpdateExpression": "SET jobStatus = :jobStatus",
"ExpressionAttributeValues": {
":username": {"S": username},
":jobStatus": {"S": "CLOSED"},
},
"ReturnValuesOnConditionCheckFailure": "ALL_OLD",
}
},
{
"Update": {
"TableName": os.environ["TABLE_NAME"],
"Key": {
"PK": {"S": f"JOB#{jobId}#APPLICATION#{applicationId}"},
"SK": {"S": f"JOB#{jobId}#APPLICATION#{applicationId}"},
},
"UpdateExpression": "SET jobApplicationStatus= :jobApplicationStatus",
"ExpressionAttributeValues": {
":jobApplicationStatus": {"S": applicationStatus},
},
"ReturnValuesOnConditionCheckFailure": "ALL_OLD",
}
},
],
ReturnConsumedCapacity="TOTAL",
ReturnItemCollectionMetrics="SIZE",
I used a transact write DynamoDB request to make sure that when a job application has been selected, the job should also be closed. One shouldn’t be true without the other being true as well.
Declining all other job applications(changing application status to DECLINED)
"""
create a for loop and send all queue messages
"""
for item in response_items["Items"][1:]:
logger.debug(
"sending messages to sqs {}".format(
json.dumps(item, default=handle_decimal_type)
)
)
if item["id"] != applicationId:
queue.send_message(
MessageBody=json.dumps(item, default=handle_decimal_type)
)
else:
logger.info(
"Accepted applicationId. So we don't have to put it into SQS"
)
# you can send a notification or an email to the accepted user here
I had to avoid doing any computations on the main thread because there could be hundreds or even thousands of job applications.
This was a great opportunity to use an SQS Queue to decouple my application and let another lambda function poll and do the computation efficiently.
Issues I saw with this approach
- Error handling within the lambda function was difficult. What if the request to get all job applications fails?
- What if an item fails to be sent into an SQS queue?
- This lambda function doesn’t adhere to the single responsibility principle.
Generally, when you have to carry out tasks within a lambda function in a sequential fashion, opt-in for services that provide the right tools to do so. i.e. Step functions.
Automating with an Express Step Function.
AWS Step Functions is a serverless orchestration service that enables you to coordinate the components of distributed applications and microservices using visual workflows.
It is a managed service that allows you to create and execute workflows to automate a wide variety of tasks.
There are two types of AWS Step Functions workflows:
- Standard workflows: These workflows have exactly-once execution and can run for up to one year. This means that each step in a Standard workflow will execute exactly once.
- Express workflows: In contrast, Express workflows have at-least-once workflow execution and can run for up to five minutes. This means that each step in an Express workflow may execute more than once, but it will always execute at least once.
For our use case, I used an Express Workflows to automate the lambda function code because they are short-lived and suitable for our needs.
Here’s the final output
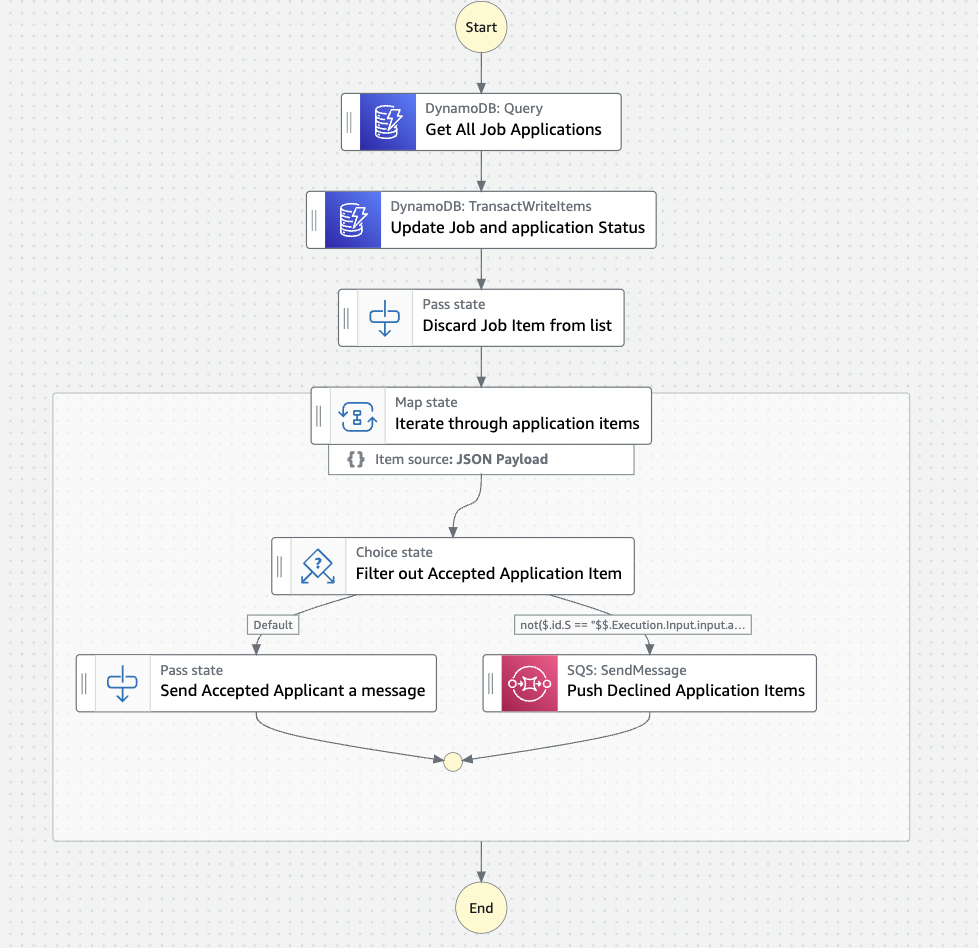
If you need a clear and concise step-by-step description of how I built this, please follow this link Building a nanny booking API.
As you can see from the visual workflow above, I was mainly doing drag, drop, and configurations. All the application code was replaced with platform code, AKA direct service integrations. I used no lambda function either.
Performance Benchmarking
To assert the fact that, refactoring the code actually improved performance, I used vegeta to run 50 transactions per second for 60 seconds on both the lambda function code and the refactored express step functions workflow. Here are the results
Check out the latencies.
Express Stepfunction
Requests [total, rate, throughput]
3000, 50.02, 49.75
------------------------------------
Duration [total, attack, wait]
1m0s, 59.98s, 327.514ms
--------------------------------------
Latencies [min, mean, 50, 90, 95, 99, max]
260.937ms, 373.937ms, 343.769ms, 480.176ms, 544.639ms, 928.78ms, 1.555s
----------------------------------------------------------------------
Lambda Function
Requests [total, rate, throughput]
3000, 50.02, 49.26
--------------------------------------------------------------------
Duration [total, attack, wait]
1m1s, 59.976s, 930.822ms
-------------------------------------------------------------------
Latencies [min, mean, 50, 90, 95, 99, max]
267.713ms, 549.823ms, 457.517ms, 606.87ms, 720.902ms, 2.723s, 3.432s
---------------------------------------------------------------------
The express step functions took half the time it took for the lambda function to complete.
I call that a huge performance improvement.
As for the cost of running such a system, I’m still doing some tests and will report back in the next post.
If you are interested in seeing how I built this API or other APIs, do check out the workshop at https://www.educloud.academy/.
Conclusion
In conclusion, refactoring can greatly improve application performance, and with the availability of some cloud tools services like the AWS Step function, the process is even easier. By automating the process and replacing application code with direct service integrations, developers can achieve significant improvements in speed and efficiency. While there may be some additional cost considerations, the benefits of serverless architecture make it a worthwhile investment for many organizations. As technology continues to evolve, it is important to stay up-to-date and explore new tools and techniques that can help optimize application performance.
Thanks for Reading, Peace Out ✌🏾