Build a GraphQL API on AWS with CDK, Python, AppSync, and DynamoDB(Part 1)
For Beginners
R
I love creating and writing about the creation of software.
Search for a command to run...
For Beginners
I love creating and writing about the creation of software.
Looks cool! I would be interested in how you create the VTL templates or lambda resolvers :)
Checkout part 2 https://phatrabbitapps.com/build-a-graphql-api-on-aws-with-cdk-python-appsync-and-dynamodbpart-2
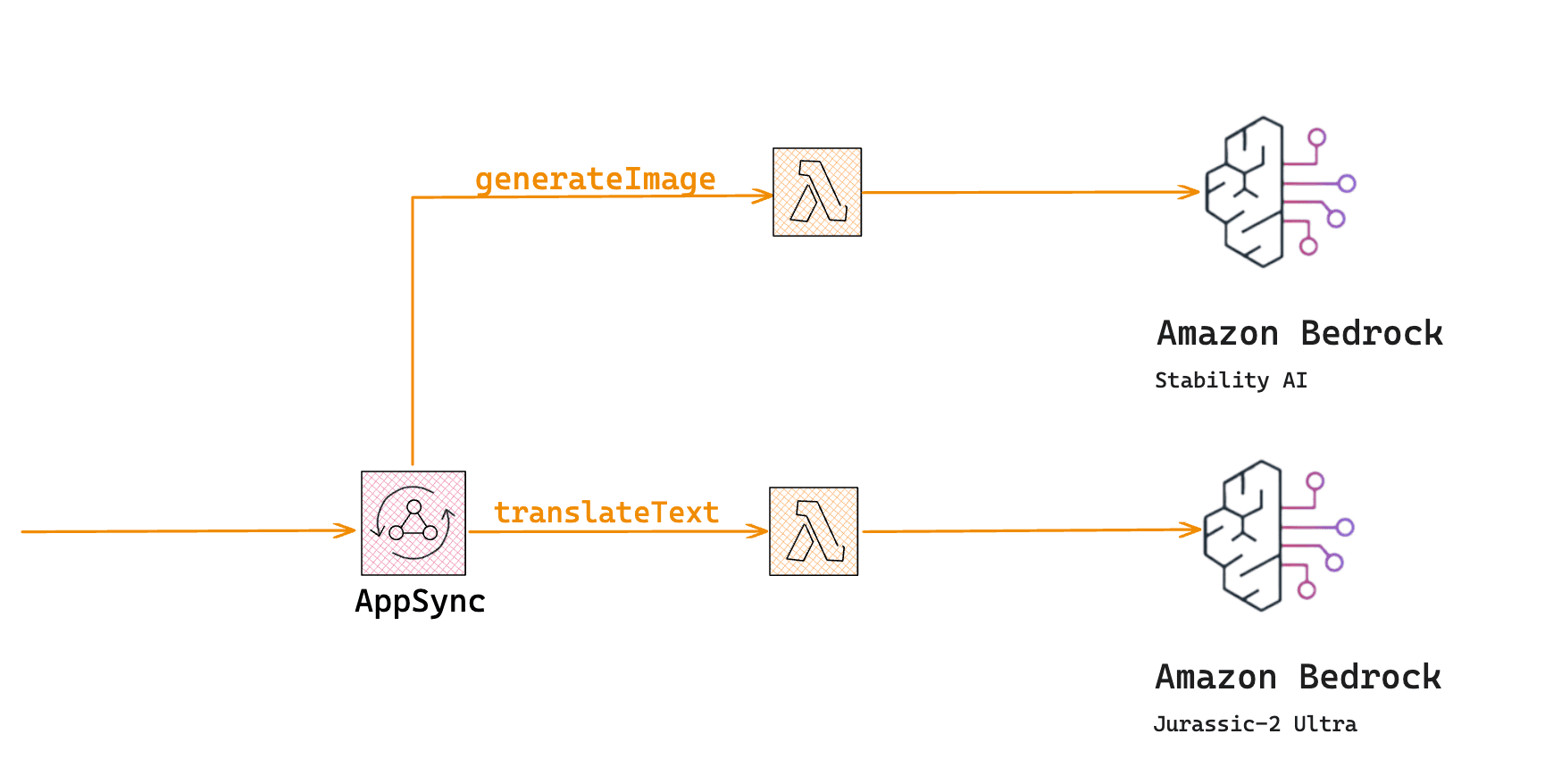
Watch the complete Video on Youtube https://www.youtube.com/watch?v=kKX-8L_R2XM Prerequisites Before proceeding make sure you have these dependencies Docker Python 3.11 and above AWS CLI Full access to a foundation model. For this workshop, we'll...

Introduction In a previous workshop, Building event-driven applications with AWS sam and python we built an e-commerce ordering service using AWS SAM, API Gateway, Lambda and Python. Here's the solutions architecture. In that workshop, whenever a ne...

Github Repository https://github.com/EducloudHQ/introduction_to_gen_ai Skill up with serverless on Educloud https://www.educloud.academy/content/da99ad07-7efa-41e7-ba50-b18e6b89e10d This post is an introductory lesson to building AI-enhanced serverle...
Introduction Serverless computing is a cloud-based approach to application development that eliminates the need for provisioning and managing servers. Instead, developers focus on writing code that is triggered by events such as HTTP requests or data...

https://github.com/trey-rosius/sam_stepfunctions Hey!!! How you doing? In this post, we’ll look at how to build a workflow, using SAM as IaC, Appsync, and python. Prerequisites Install AWS Cli (https://docs.aws.amazon.com/cli/latest/userguide/cli-c...

AWS CDK provides us with high-level components called constructs that preconfigure cloud resources with proven defaults, so you can build cloud applications without needing to be an expert.
We will be using Appsync and DynamoDB constructs for this exercise
mkdir cdkTrainer && cd cdkTrainer
We will use cdk init to create a new Python CDK project:
cdk init app --language python
Once created, you should see a bunch of output. Ignore the warnings if any.
Open up the folder in your favorite IDE and click on the README.md file.
To take advantage of the virtual environment that was created, you have to activate it within your shell. The generated README file provides all of this information.
To activate your virtualenv on a Linux or MacOs platform
source .venv/bin/activate
For Windows
.venv\Scripts\activate.bat
Once activated, add these python modules, which are cdk constructs to your requirement.txt file.
aws-cdk.core
aws-cdk.aws-appsync
aws-cdk.aws-dynamodb
aws-cdk.aws-iam
Install the modules by running this command
pip install -r requirements.txt
We are creating a GraphQL API which would be assessed by an API_KEY through AppSync and data stored and retrieved from the DynamoDB.
Contructs represent AWS resources which we will be using and they are the basic building blocks of AWS CDK apps. They also encapsulate everything AWS CloudFormation needs to create the component.
Since we will be needing an API_KEY,AppSync, and DynamoDB to create and access our GraphQL API, we've installed the AWS constructs for each of them.
Here's a list of other available constructs.
AWS Python Constructs
cdkTrainer — A Python module directory.
cdk_trainer_stack.py—A custom CDK stack construct for use in your CDK application.
app.py — The “main” for this application.
#!/usr/bin/env python3
import os
from aws_cdk import core as cdk
# For consistency with TypeScript code, `cdk` is the preferred import name for
# the CDK's core module. The following line also imports it as `core` for use
# with examples from the CDK Developer's Guide, which are in the process of
# being updated to use `cdk`. You may delete this import if you don't need it.
from aws_cdk import core
from cdk_trainer.cdk_trainer_stack import CdkTrainerStack
app = core.App()
CdkTrainerStack(app, "CdkTrainerStack",env={
'account':'xxxxxxxxxx',
'region': 'us-east-2'}
# If you don't specify 'env', this stack will be environment-agnostic.
# Account/Region-dependent features and context lookups will not work,
# but a single synthesized template can be deployed anywhere.
# Uncomment the next line to specialize this stack for the AWS Account
# and Region that are implied by the current CLI configuration.
#env=core.Environment(account=os.getenv('CDK_DEFAULT_ACCOUNT'), region=os.getenv('CDK_DEFAULT_REGION')),
# Uncomment the next line if you know exactly what Account and Region you
# want to deploy the stack to. */
#env=core.Environment(account='123456789012', region='us-east-1'),
# For more information, see https://docs.aws.amazon.com/cdk/latest/guide/environments.html
)
app.synth()
This code loads and instantiates an instance of the CdkTrainerStack class from cdkTrainer/cdk_trainer_stack.py file.
Make sure you edit the 'account' and 'region' values.
from aws_cdk import core as cdk
from aws_cdk.aws_appsync import (
CfnGraphQLSchema,
CfnGraphQLApi,
CfnApiKey,
MappingTemplate,
CfnDataSource, CfnResolver
)
from aws_cdk.aws_dynamodb import (
Table,
Attribute,
AttributeType,
StreamViewType,
BillingMode,
)
from aws_cdk.aws_iam import (
Role,
ServicePrincipal,
ManagedPolicy
)
class CdkTrainerStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
class CdkTrainerStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# The code that defines your stack goes here
trainers_graphql_api = CfnGraphQLApi(
self,'trainersApi',
name="trainers-api",
authentication_type='API_KEY'
)
A few things to note ....
This is because all of these classes are constructs as mentioned earlier. Constructs are the basic building block of CDK apps. They represent abstract “cloud components” which can be composed together into higher-level abstractions via scopes. Scopes can include constructs, which in turn can include other constructs, etc.
Constructs are always created in the scope of another construct and must always have an identifier that must be unique within the scope it’s created. Therefore, construct initializers (constructors) will always have the following signature:
For example, the CfnGraphQLApi construct accepts arguments like name,authentication_type etc.
You can explore the various options using your IDE’s auto-complete or in the online documentation.
table_name = "trainers
dirname = os.path.dirname(__file__)
with open(os.path.join(dirname, "../graphql/schema.txt"), 'r') as file:
data_schema = file.read().replace('\n', '')
CfnApiKey(
self,'TrainersApiKey',
api_id = trainers_graphql_api.attr_api_id
)
api_schema = CfnGraphQLSchema(
self,"TrainersSchema",
api_id = trainers_graphql_api.attr_api_id,
definition=data_schema
)
We have to define the schema for your application and feed it as a string to the definition argument of CfnGraphQLSchema.
Within the root folder of your project, create a folder called GraphQl, then create a file within it called schema.txt and type in the following schema.
type Trainers {
id: ID!
firstName:String!
lastName:String!
age:Int!
specialty:Specialty
}
enum Specialty{
BODYBUILDING,
YOUTHFITNESS,
SENIORFITNESS,
CORRECTIVEEXERCISE
}
type PaginatedTrainers {
items: [Trainers!]!
nextToken: String
}
type Query {
allTrainers(limit: Int, nextToken: String): PaginatedTrainers!
getTrainer(id: ID!): Trainers
}
type Mutation {
createTrainer( firstName:String!,
lastName:String!,
age:Int!,
specialty:Specialty): Trainers
deleteTrainer(id: ID!): Trainers
updateTrainers(id: ID!,
firstName:String,
lastName:String,
age:Int,
specialty:Specialty):Trainers
}
type Schema {
query: Query
mutation: Mutation
}
trainers_table = Table(
self, 'TrainersTable',
table_name=table_name,
partition_key=Attribute(
name='id',
type=AttributeType.STRING,
),
billing_mode=BillingMode.PAY_PER_REQUEST,
stream=StreamViewType.NEW_IMAGE,
# The default removal policy is RETAIN, which means that CDK
# destroy will not attempt to delete the new table, and it will
# remain in your account until manually deleted. By setting the
# policy to DESTROY, cdk destroy will delete the table (even if it
# has data in it)
removal_policy=core.RemovalPolicy.DESTROY # NOT recommended for production code
)
trainers_table_role = Role(
self, 'TrainersDynamoDBRole',
assumed_by=ServicePrincipal('appsync.amazonaws.com')
)
trainers_table_role.add_managed_policy(
ManagedPolicy.from_aws_managed_policy_name(
'AmazonDynamoDBFullAccess'
)
)
data_source = CfnDataSource(
self, 'TrainersDataSource',
api_id=trainers_graphql_api.attr_api_id,
name='TrainersDynamoDataSource',
type='AMAZON_DYNAMODB',
dynamo_db_config=CfnDataSource.DynamoDBConfigProperty(
table_name=trainers_table.table_name,
aws_region=self.region
),
service_role_arn=trainers_table_role.role_arn
)
With all these in place, it's time to create our resolvers.
Resolvers simply connect the fields of our user type in the above schema to a datasource, in this case, DynamoDB.
Let me know what you think about this piece. I'll appreciate any feedback.
Stay Safe ✌🏿